This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I’d like to share a story about an educational side project which could prove fruitful for a software engineer who’s seeking a new job. Juraj created a systems design explainer on how he built this project, and the technologies used: The systems design diagram for the Rides application The app uses: Node.js Persistence.
Projects 3.1. Projects from least to most complex 3.2. Introduction 2. Run Data Pipelines 2.1. Run on codespaces 2.2. Run locally 3. Batch pipelines 3.3. Stream pipelines 3.4. Event-driven pipelines 3.5. LLM RAG pipelines 4. Conclusion 1.
cross-project dependencies ( credits ) Over the last few years, dbt has become a de facto standard enabling companies to collaborate easily on data transformations. Whatever the number, there will be a critical point at which a single project no longer scale. Cross-project references is a key enabler to data team decentralisation.
Aspiring data engineers often seek real-world projects to gain hands-on experience and showcase their expertise. This article presents the top 20 data engineering project ideas with their source code. Whether you’re […] The post Top 20 Data Engineering Project Ideas [With Source Code] appeared first on Analytics Vidhya.
In this White Paper, Logi Analytics has identified 5 tell-tale signs your project is moving from “nice to have” to “needed yesterday.". Many application teams leave embedded analytics to languish until something—an unhappy customer, plummeting revenue, a spike in customer churn—demands change. But by then, it may be too late.
Introduction 2. Objective 3. Prerequisite 4.2 AWS Infrastructure costs 4.3 Data lake structure 5. Code walkthrough 5.1 Loading user purchase data into the data warehouse 5.2 Loading classified movie review data into the data warehouse 5.3 Generating user behavior metric 5.4. Checking results 6. Tear down infra 7. Design considerations 8.
Were thrilled to announce the release of a new Cloudera Accelerator for Machine Learning (ML) Projects (AMP): Summarization with Gemini from Vertex AI . The post Introducing Accelerator for Machine Learning (ML) Projects: Summarization with Gemini from Vertex AI appeared first on Cloudera Blog.
Where can you find projects dealing with advanced ML topics? GitHub is a perfect source with its many repositories. I’ve selected ten to talk about in this article.
Speaker: Ryan MacCarrigan, Founding Principal, LeanStudio
Watch this webinar with Ryan MacCarrigan, Founding Principal of LeanStudio, to learn about key considerations for launching your next analytics project. But what happens when you have a growing user base and additional feature requests?
Each project, from beginner tasks like Image Classification to advanced ones like Anomaly Detection, includes a link to the dataset and source code for easy access and implementation.
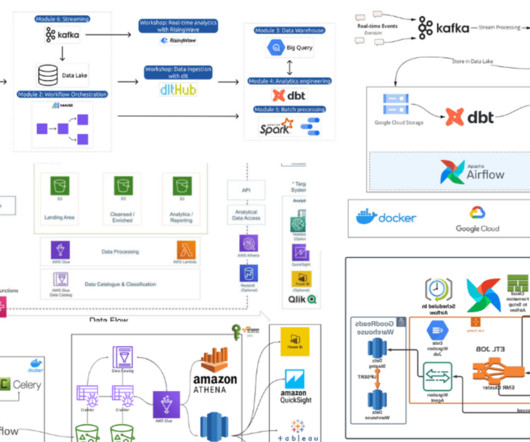
Introduction 2. Parts of data engineering 3.1. Requirements 3.1.1. Understand input datasets available 3.1.2. Define what the output dataset will look like 3.1.3. Define SLAs so stakeholders know what to expect 3.1.4. Define checks to ensure the output dataset is usable 3.2. Identify what tool to use to process data 3.3. Data flow architecture 3.
Every time an application team gets caught up in the “build vs buy” debate, it stalls projects and delays time to revenue. There is a third option. Partnering with an analytics development platform gives you the freedom to customize a solution without the risks and long-term costs of building your own.
Doing data science projects can be demanding, but it doesnt mean it has to be boring. Here are four projects to introduce more fun to your learning and stand out from the masses.
Data engineering is best learned by doing projects. Here are six projects focusing on different data engineering skills to ensure you have it all covered. But which ones?
To solve this, we’ll apply Projection Policies to ensure that only certain roles can see sensitive columns like Customer numbers. Snowflake provides several layers of data security, including Projection Policies , Masking Policies , and Row Access Policies , that work together to restrict access based on roles.
You'll learn: Why every product leader goes into a new project with untested, hidden assumptions. Watch this webinar with Laura Klein, product manager and author of Build Better Products, to learn how to spot the unconscious assumptions which you’re basing decisions on and guidelines for validating (or invalidating) your ideas.
Ways to reuse seed data across multiple dbt projects 2.1. Setup project environment 2.2. Store your package for other dbt projects to reference 2.3. Use project dependencies (dbt enterprise only) 2.4. Introduction 2. Code setup 2.1.1. Prerequisites 2.1.2. Turn the source repo into a dbt package 2.2.1.
What should product managers keep in mind when adding an analytics project to their roadmap? What are best practices when designing the UI and UX of embedded dashboards, reports, and analytics? What should software teams know about implementing security that works with the rest of their products?
Data contracts was a hot topic in the data space before LLMs and GenAI came out. They promised a better world with less communication issues between teams, leading to more reliable and trustworthy data. Unfortunately, the promise has been too hard to put into practice. Has been, or should I write "was"?
In this post, you'll learn what BigQuery is, understand its capabilities, and set up a project in Google Cloud which we will later use to practice using BigQuery for loading, querying, and analyzing data.
When working on a project, think beyond traditional data sources. Explore unconventional options like social media and user-generated content for fresh insights.
Every data-driven project calls for a review of your data architecture—and that includes embedded analytics. Before you add new dashboards and reports to your application, you need to evaluate your data architecture with analytics in mind.
Steps to decide on a data project to build 2.1. Introduction 2. Objective 2.2. Research 2.2.1. Job description 2.2.2. Potential referral/hiring manager research 2.2.3. Company research 2.3. Data 2.3.1. Dataset Search 2.3.2. Generate fake data 2.4. Outcome 2.4.1. Visualization 2.5. Presentation 3. Conclusion 4. Read these 1.
Versioning Best Practices for Data Science Projects As I have mentioned, this article assumes you have basic versioning knowledge. You don’t necessarily need to be adept at it, but at least you already have a Git version tool in the environment. If you haven’t, please follow the instructions for installation on the Git website.
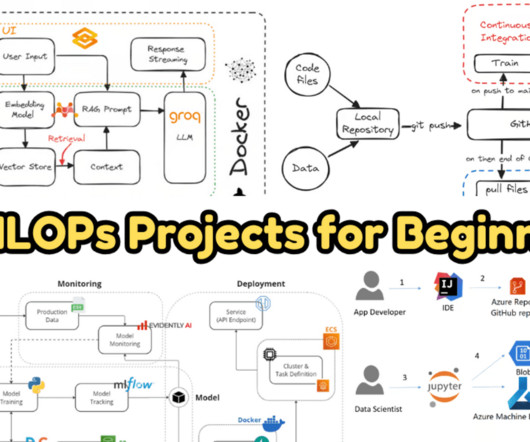
Learn model serving, CI/CD, ML orchestration, model deployment, local AI, and Docker to streamline ML workflows, automate pipelines, and deploy scalable, portable AI solutions effectively.
The data science lifecycle of a project outlines the […] The post Life Cycle of Data Science Project appeared first on WeCloudData. Data is shaping our decisions, from personalized shopping experiences to checking weather forecasts before leaving home. All of these data science applications have a life cycle to follow.
Great dashboards lead to richer user experiences and significant return on investment (ROI), while poorly designed dashboards distract users, suppress adoption, and can even tarnish your project or brand.
NLP plays a crucial role in multiple domains and NLP projects ranging from its automating customer service, improving search engines, or analyzing social media sentiments. Natural Language Processing (NLP) has transformed technology by allowing machines to understand, decode, and generate human language.
In this article, Im going to share data science project ideas that will actually help you stand out. These are creative projects that solve problems with data, and Ive included source code and tutorials to help you replicate them.
Inside you will learn: How embedded analytics has become essential to business applications When to buy an embedded analytics solution and when to build one How to go-to-market, from pricing and packaging to external promotion How to build a business case and sell the project internally The future of embedded analytics …plus so much more.
This project helped onboard me to the software, its structure, its build, and our issue tracking and version control workflows. My first project was supporting i18n (internationalization) in the app. They hired a manager who had done this kind of project before, and set a target date of nearly two years.
In particular, we expect both Business Intelligence and Data Engineering will be driven by AI operating on top of the context defined in your dbt Projects. Weve known for a while that the combination of structured data from your dbt project + LLMs is a potent combo (particularly when using the dbt Semantic Layer).
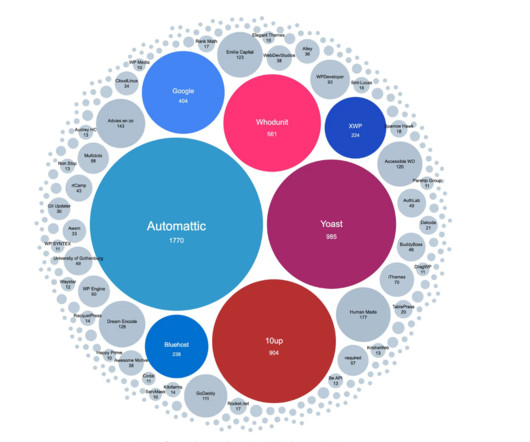
Heavy development investment: Automattic – a VC-funded company founded by Matt Mullenweg – is the largest contributor to Wordpress, paying more than 100 staff to work full-time on the project. ” HashiCorp is facing similar challenges with Terraform / OpenTofu.
It begins with a clean state, and can ship something that works for, say, 90% of existing Node projects, and break the remaining 10%. I tip my hat to all volunteer open source contributors and maintainers — both for Node, and for other projects. Bun has no such constraint. If you are one of these people: thank you!
Speaker: Aindra Misra, Sr. Staff Product Manager of Data & AI at BILL (Previously PM Lead at Twitter/X)
Anticipated future use cases as we project into 2024 and beyond. Examine real world use cases, both internal and external, where data analytics is applied, and understand its evolution with the introduction of Gen AI.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content