This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I’d like to share a story about an educational side project which could prove fruitful for a software engineer who’s seeking a new job. Juraj included system monitoring parts which monitor the server’s capacity he runs the app on: The monitoring page on the Rides app And it doesn’t end here. Persistence.
Were explaining the end-to-end systems the Facebook app leverages to deliver relevant content to people. At Facebooks scale, the systems built to support and overcome these challenges require extensive trade-off analyses, focused optimizations, and architecture built to allow our engineers to push for the same user and business outcomes.
Summary Any software system that survives long enough will require some form of migration or evolution. When that system is responsible for the data layer the process becomes more challenging. Sriram Panyam has been involved in several projects that required migration of large volumes of data in high traffic environments.
Buck2 is a from-scratch rewrite of Buck , a polyglot, monorepo build system that was developed and used at Meta (Facebook), and shares a few similarities with Bazel. As you may know, the Scalable Builds Group at Tweag has a strong interest in such scalable build systems. Meta recently announced they have made Buck2 open-source.
Provide those dependencies such that the build system can find them. Run the build system. This allows for irreproducible builds, and makes it easy to forget to explicitly list a system dependency if it happens to be installed on the author’s system. Also, the templates are suited to building opam projects.
Data transfer systems are a critical component of data enablement, and building them to support large volumes of information is a complex endeavor. With Datafold, you can seamlessly plan, translate, and validate data across systems, massively accelerating your migration project.
In the early 90’s, DOS programs like the ones my company made had its own Text UI screen rendering system. This rendering system was easy for me to understand, even on day one. Our rendering system was very memory inefficient, but that could be fixed. By doing so, I got to see every screen of the system.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. 2019 - Delta Lake Databricks released Delta Lake as an open-source project.
Buck2, our new open source, large-scale build system , is now available on GitHub. Buck2 is an extensible and performant build system written in Rust and designed to make your build experience faster and more efficient. In particular, we support Sapling-based file systems. Why rebuild Buck?
In particular, we expect both Business Intelligence and Data Engineering will be driven by AI operating on top of the context defined in your dbt Projects. Both AI agents and business stakeholders will then operate on top of LLM-driven systems hydrated by the dbt MCP context. Why does this matter? MCP addresses this challenge.
The title of the book takes aim at the “myth” that software development can be measured in “man months,” which Brooks disproves in the pages that follow: “Cost [of the software project] does indeed vary as the product of the number of men and the number of months. Progress does not. Two secretaries.
Summary Data engineering is all about building workflows, pipelines, systems, and interfaces to provide stable and reliable data. Datafold has invested a lot of time into integrating with the workflow of dbt projects to add early verification that the changes you are making are correct. What are the parallels to that in data projects?
You can find the online PMP exam application on the Project Management Institute (PMI)® website. Check Project Management professional preparation course to get started with your PMP preparation. Work Experience Your project management expertise is questioned in the next area of the online form.
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. We dabbled in network engineering, database management, and system administration. and hand-rolled C -code.
To bring observability to dbt projects the team at Elementary embedded themselves into the workflow. Can you start by outlining what elements of observability are most relevant for dbt projects? Over the past ~3 years there were numerous data observability systems/products created. How is Elementary designed/implemented?
It begins with a clean state, and can ship something that works for, say, 90% of existing Node projects, and break the remaining 10%. I tip my hat to all volunteer open source contributors and maintainers — both for Node, and for other projects. Bun has no such constraint. If you are one of these people: thank you!
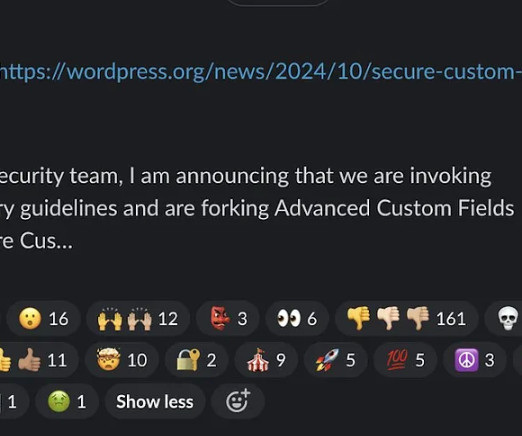
Corporate conflict recap Automattic is the creator of open source WordPress content management system (CMS), and WordPress powers an incredible 43% of webpages and 65% of CMSes. OpenAI’s impossible business projections. According This event is shameful and unprecedented in the history of open source on the web.
Say Harish and Lisa are two people working on the same project but on two different systems(say windows and […] The post Getting Started with The Basics of Docker appeared first on Analytics Vidhya. ” If you read the above quote, you must think, what does this all mean? Well, my friend, this is what Docker is.
Introduction Apache Cassandra is a NoSQL database management system that is open-source and distributed. Facebook created Cassandra, which ultimately became an Apache Software Foundation project. It is well-known for its rapid write […] The post Top 6 Cassandra Interview Questions appeared first on Analytics Vidhya.
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
We recently covered how CockroachDB joins the trend of moving from open source to proprietary and why Oxide decided to keep using it with self-support , regardless Web hosting: Netlify : chosen thanks to their super smooth preview system with SSR support. Internal comms: Chat: Slack Coordination / project management: Linear 3.
There are multiple ways to start a new year, either with new projects, new ideas, new resolutions or by just keeping doing the same music. AI companies are aiming for the moon—AGI—promising it will arrive once OpenAI develops a system capable of generating at least $100 billion in profits. I hope you will enjoy 2025.
Project demo 3. Distributed systems are scalable, resilient to failures, & designed for high availability 4.5. Introduction 2. Building efficient data pipelines with DuckDB 4.1. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3.
Senior Engineers are not only expected to lead significant projects in their teams, but they have a say in whether that feature is worth building or not. The SDE3 level expects leadership on projects in which this engineer is involved. It’s not a checklist, but some expectations that could be considered: Lead a complex project.
Wordpress is the most popular content management system (CMS), estimated to power around 43% of all websites; a staggering number! As a response, cloud providers started the Valkey project, which could become the “new and still permissive Redis.”
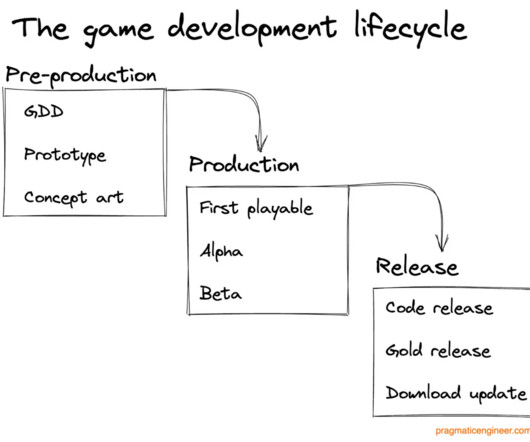
Tommy has built his own video games, consulted on a wide variety of game projects, and for a decade has taught game development at various universities. Each project typically takes several years to create, with shifting hardware specifications and emerging competitors and trends to anticipate and react to, during the process.
Beyond working with well-structured data in a data warehouse, modern AI systems can use deep learning and natural language processing to work effectively with unstructured and semi-structured data in data lakes and lakehouses. AI projects should not be about “the latest” or “the best.” Leadership will be the antidote to AI exhaustion.
From Sella’s status page : “Following the installation of an update to the operating system and related firmware which led to an unstable situation. Still, I’m puzzled by how long the system has been down. If it was an update to Oracle, or to the operating system, then why not roll back the update?
Thats why we are announcing that SnowConvert , Snowflakes high-fidelity code conversion solution to accelerate data warehouse migration projects, is now available for download for prospects, customers and partners free of charge. And today, we are announcing expanded support for code conversions from Amazon Redshift to Snowflake.
The project showed that smaller, empowered teams achieve higher impact than larger ones. These small, cross-functional teams ensured that members were deeply involved in the project operations, the technical setup, and the feedback cycle, leading to fewer delays, fewer bottlenecks, and faster decision-making.
Are you looking for an easier way to manage files across different storage systems? fsspec is a Python library that simplifies file handling by providing a unified interface for file management.
We present a high level overview of our in-house phone masking system and dive into the details of the engineering challenge of optimizing the usage of proxy phone number resources at Yelp’s scale. Background Every year, millions of requests for quotes, consultations or other messages are sent to businesses on Yelp.
Multiple open source projects and vendors have been working together to make this vision a reality. What are the pain points that are still prevalent in lakehouse architectures as compared to warehouse or vertically integrated systems? If you've learned something or tried out a project from the show then tell us about it!
Willem Spruijt is a software engineer whom I worked on the same team with at Uber in Amsterdam, building payments systems. So we had a quarterly planning process to ensure all project dependencies were incorporated into each team’s roadmap. We cover one out of four topics in today’s subscriber-only The Pulse issue.
Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Data projects are notoriously complex. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects.
Thats why we are announcing that SnowConvert , Snowflakes high-fidelity code conversion solution to accelerate data warehouse migration projects, is now available for download for prospects, customers and partners free of charge. And today, we are announcing expanded support for code conversions from Amazon Redshift to Snowflake.
They called it Office 365, and in 2010, this was a really exciting project to work on. I wrote code for drivers on Windows, and started to put a basic observability system in place. EC2 had no observability system back then: people would spin up EC2 instances but have no idea whether or not they worked.
Document RAG preparation : Ingesting, cleaning and chunking documents before embedding them into vector representations, enabling efficient retrieval and enhanced LLM responses in retrieval-augmented generation (RAG) systems. An efficient batch processing system scales in a cost-effective manner to handle growing volumes of unstructured data.
” A few days ago on 27 February, Klarna shared progress, a month after the project went live. With clever-enough probing, this system prompt can be revealed. ” What is the system prompt for Klarna’s bot? ’ The two companies have worked together ever since.” Translate to English if needed.
Additionally, multiple copies of the same data locked in proprietary systems contribute to version control issues, redundancies, staleness, and management headaches. This dampens confidence in the data and hampers access, in turn impacting the speed to launch new AI and analytic projects.
I still remember being in a meeting where a Very Respected Engineer was explaining how they are building a project, and they said something along the lines of "and, of course, idempotency is non-negotiable." I was sceptical that any system would automatically reject resumes, because I never saw this as a hiring manager.
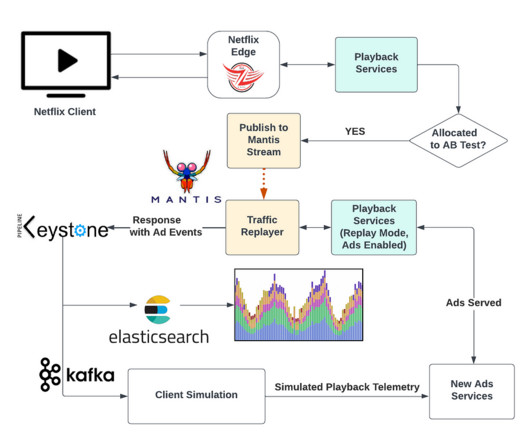
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. Replay traffic enabled us to test our new systems and algorithms at scale before launch, while also making the traffic as realistic as possible.
System metrics, such as inference latency and throughput, are available as Prometheus metrics. Users can manage all of their models and applications on the Cloudera AI Inference service with common CI/CD systems using Cloudera service accounts, also known as machine users.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content