This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to data architecture and structureddata management that really hit its stride in the early 1990s.
Traditionally, SQL has been limited to structureddata neatly organized in tables. Snowflake will be introducing new multimodal SQL functions (private preview soon) that enable data teams to run analytical workflows on unstructureddata, such as images.
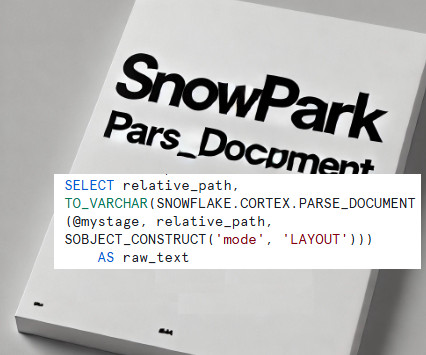
Read Time: 2 Minute, 33 Second Snowflakes PARSE_DOCUMENT function revolutionizes how unstructureddata, such as PDF files, is processed within the Snowflake ecosystem. Traditionally, this function is used within SQL to extract structured content from documents. Apply advanced data cleansing and transformation logic using Python.
Introduction A data lake is a centralized and scalable repository storing structured and unstructureddata. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
We will also address some of the key distinctions between platforms like Hadoop and Snowflake, which have emerged as valuable tools in the quest to process and analyze ever larger volumes of structured, semi-structured, and unstructureddata.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
Understanding data warehouses A data warehouse is a consolidated storage unit and processing hub for your data. Teams using a data warehouse usually leverage SQL queries for analytics use cases. This same structure aids in maintaining data quality and simplifies how users interact with and understand the data.
Structuringdata refers to converting unstructureddata into tables and defining data types and relationships based on a schema. The data lakes store data from a wide variety of sources, including IoT devices, real-time social media streams, user data, and web application transactions.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
Businesses benefit at large with these data collection and analysis as they allow organizations to make predictions and give insights about products so that they can make informed decisions, backed by inferences from existing data, which, in turn, helps in huge profit returns to such businesses. What is the role of a Data Engineer?
Despite these limitations, data warehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications. While data warehouses are still in use, they are limited in use-cases as they only support structureddata.
Data Science is the field that focuses on gathering data from multiple sources using different tools and techniques. Whereas, Business Intelligence is the set of technologies and applications that are helpful in drawing meaningful information from rawdata. Business Intelligence only deals with structureddata.
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structureddata? Consider whether you need a solution that supports one or multiple data formats.
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structureddata? Consider whether you need a solution that supports one or multiple data formats.
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structureddata? Consider whether you need a solution that supports one or multiple data formats.
Generally data to be stored in the database is categorized into 3 types namely StructuredData, Semi StructuredData and UnstructuredData. We generally refer to UnstructuredData as “Big Data” and the framework that is used for processing Big Data is popularly known as Hadoop.
In today's world, where data rules the roost, data extraction is the key to unlocking its hidden treasures. As someone deeply immersed in the world of data science, I know that rawdata is the lifeblood of innovation, decision-making, and business progress. What is data extraction?
Having a sound knowledge of either of these programming languages is enough to have a successful career in Data Science. Excel Excel is another very important prerequisite for Data Science. It is an important tool to understand, manipulate, analyze and visualize data.
Difference Between Data Warehouse and Data Lake When looking at the difference between data lake and data warehouse, the following key properties distinguish data lakes vs data warehouses. Data lakes accept and store rawdata in any format.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Data sources can be broadly classified into three categories.
Cleaning Bad data can derail an entire company, and the foundation of bad data is unclean data. Therefore it’s of immense importance that the data that enters a data warehouse needs to be cleaned. Data can be loaded in batches or can be streamed in near real-time.
Organisations and businesses are flooded with enormous amounts of data in the digital era. Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Data processing analysts can be useful in this situation.
DL models automatically learn features from rawdata, eliminating the need for explicit feature engineering. Data Types and Dimensionality ML algorithms work well with structured and tabular data, where the number of features is relatively small.
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace.
More importantly, we will contextualize ELT in the current scenario, where data is perpetually in motion, and the boundaries of innovation are constantly being redrawn. Extract The initial stage of the ELT process is the extraction of data from various source systems. What Is ELT? So, what exactly is ELT?
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structureddata comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers.
A single car connected to the Internet with a telematics device plugged in generates and transmits 25 gigabytes of data hourly at a near-constant velocity. And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data.
Common Tools Data Sources Identification with Apache NiFi : Automates data flow, handling structured and unstructureddata. Used for identifying and cataloging data sources. Data Storage with Apache HBase : Provides scalable, high-performance storage for structured and semi-structureddata.
You have probably heard the saying, "data is the new oil". It is extremely important for businesses to process data correctly since the volume and complexity of rawdata are rapidly growing. However, the vast volume of data will overwhelm you if you start looking at historical trends. Well, it surely is!
In data lakes, data is distributed, making it difficult to document as data evolves over the course of its lifecycle. Unstructureddata is problematic as it relates to data catalogs because it’s not organized, and if it is, it’s often not declared as organized. Image courtesy of Barr Moses.
By accommodating various data types, reducing preprocessing overhead, and offering scalability, data lakes have become an essential component of modern data platforms , particularly those serving streaming or machine learning use cases. AWS is one of the most popular data lake vendors.
A data hub, in turn, is rather a terminal or distribution station: It collects information only to harmonize it, and sends it to the required end-point systems. Data lake vs data hub. A data lake is quite opposite of a DW, as it stores large amounts of both structured and unstructureddata.
Purpose-built, data warehouses allow for making complex queries on structureddata via SQL (Structured Query Language) and getting results fast for business intelligence. Traditional data warehouse platform architecture. Another type of data storage — a data lake — tried to address these and other issues.
For example, unlike traditional platforms with set schemas, data lakes adapt to frequently changing datastructures at points where the data is loaded , accessed, and used. They can accommodate any type of data, from structured to semi-structured to unstructured, and do not need a predefined schema.
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
Analyzing data with statistical and computational methods to conclude any information is known as data analytics. Finding patterns, trends, and insights, entails cleaning and translating rawdata into a format that can be easily analyzed. These insights can be applied to drive company outcomes and make educated decisions.
This means that a data warehouse is a collection of technologies and components that are used to store data for some strategic use. Data is collected and stored in data warehouses from multiple sources to provide insights into business data. Data from data warehouses is queried using SQL.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structureddata, and a data lake used to host large amounts of rawdata.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content