This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the heart of these data engineering skills lies SQL that helps data engineers manage and manipulate large amounts of data. Did you know SQL is the top skill listed in 73.4% of data engineer job postings on Indeed? Almost all major tech organizations use SQL. use SQL, compared to 61.7%
Explore beginner-friendly and advanced SQL interview questions with answers, syntax examples, and real-world database concepts for preparation. Looking to land a job as a data analyst or a data scientist, SQL is a must-have skill on your resume. RDBMS stands for RelationalDatabase Management System.
Master data analytics skills with unique big data analytics mini projects with source code. Amazon DynamoDB Amazon DynamoDB provides an alternative to relationaldatabase systems by using several data types, such as document, graph, key-value, memory, and search.
The process of creating logical data models is known as logical data modeling. Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers 2. How would you create a Data Model using SQL commands? You can also use the INSERT command to fill your tables with data.
So, let’s dive into the list of the interview questions below - List of the Top Amazon Data Engineer Interview Questions Explore the following key questions to gauge your knowledge and proficiency in AWS Data Engineering. Become a Job-Ready Data Engineer with Complete Project-Based Data Engineering Course !
The distributed collection of structureddata is called a PySpark DataFrame. They are stored in named columns and are equivalent to relationaldatabase tables. Various sources, including StructuredData Files, Hive Tables, external databases, existing RDDs, etc., How does PySpark DataFrames work?
FAQs on Graph Databases What is a Graph Database? A graph database is a specialized database designed to efficiently store and query interconnected data. The Key Components of a Graph Database include - Nodes represent entities or objects within the data, such as a person, a place, or a product.
Hadoop Sqoop and Hadoop Flume are the two tools in Hadoop which is used to gather data from different sources and load them into HDFS. Sqoop in Hadoop is mostly used to extract structureddata from databases like Teradata, Oracle, etc., They enable the connection of various data sources to the Hadoop environment.
What are DBT macros, and how do they enhance SQL functionality in DBT? DBT (Data Build Tool) macros are reusable pieces of SQL code written in Jinja – a templating language that enhances SQL's functionality by enabling dynamic and modular code creation. How can DBT be used to handle incremental data loads?
With SQL, machine learning, real-time data streaming, graph processing, and other features, this leads to incredibly rapid big data processing. DataFrames are used by Spark SQL to accommodate structured and semi-structureddata. Trino is a distributed SQL query engine. Trino Source: trino.io
They include relationaldatabases like Amazon RDS for MySQL, PostgreSQL, and Oracle and NoSQL databases like Amazon DynamoDB. Types of AWS Databases AWS provides various database services, such as RelationalDatabases Non-Relational or NoSQL Databases Other Cloud Databases ( In-memory and Graph Databases).
Additional libraries on top of Spark Core enable a variety of SQL, streaming, and machine learning applications. Spark can integrate with Apache Cassandra to process data stored in this NoSQL database. Spark can connect to relationaldatabases using JDBC, allowing it to perform operations on SQLdatabases.
Table of Contents What are Data Warehousing Tools? Why Choose a Data Warehousing Tool? Scalability to meet evolving data demands. Standard SQL support for querying. Flexible pricing options with encryption and data controls. Loading data can be time-consuming, especially for large volumes.
PySpark SQL and Dataframes A dataframe is a shared collection of organized or semi-structureddata in PySpark. This collection of data is kept in Dataframe in rows with named columns, similar to relationaldatabase tables. With PySparkSQL, we can also use SQL queries to perform data extraction.
Since data needs to be accessible easily, organizations use Amazon Redshift as it offers seamless integration with business intelligence tools and helps you train and deploy machine learning models using SQL commands. Amazon Redshift is helping over 10000 customers with its unique features and data analytics properties.
Here's how you can do it: Next, you need to learn how to of load data elements of structureddata into DataFrames from various data sources in PySpark using pyspark sql import functions. It is conceptually similar to a table in a relationaldatabase or a pandas DataFrame in Python.
These databases are completely managed by AWS, relieving users of time-consuming activities like server provisioning, patching, and backup. The relationaldatabases- Amazon Aurora , Amazon Redshift, and Amazon RDS use SQL (Structured Query Language) to work on data saved in tabular formats.
Data is collected and stored in data warehouses from multiple sources to provide insights into business data. Data warehouses store highly transformed, structureddata that is preprocessed and designed to serve a specific purpose. Data from data warehouses is queried using SQL.
Data transformation is a crucial task since it greatly enhances the usefulness and accessibility of data. Load - Engineers can load data to the desired location, often a relationaldatabase management system (RDBMS), a data warehouse, or Hadoop, once it becomes meaningful.
Let’s say you want to pull data from an API, clean it, and load it into an SQLdatabase or data warehouse like PostgreSQL, BigQuery , or even a local CSV file. You’d rather write it once and let the data pipeline handle it. You don’t want to do this manually every day, right?
Questions span data warehousing , ETL processes, big data technologies , SQL, data processing, optimization, security, privacy, and data visualization. The on-site assessments cover SQL , analytics, machine learning , and algorithms. How would you optimize a SQL query for a large dataset in a data warehouse?
Differentiate between relational and non-relationaldatabase management systems. RelationalDatabase Management Systems (RDBMS) Non-relationalDatabase Management Systems RelationalDatabases primarily work with structureddata using SQL (Structured Query Language).
Importance of Choosing the Correct Snowflake Data Types Build Your First Snowflake Project with ProjectPro FAQ’s 6 Snowflake Datatypes Every Data Engineer Must Know Like other relationaldatabases, there are many data types in Snowflake, including basic SQLdata types, to cater to multiple data needs.
Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional data management tools. Big data operations require specialized tools and techniques since a relationaldatabase cannot manage such a large amount of data.
Hive is a data warehousing and SQL-like query language system built on top of Hadoop. Hive provides a high-level abstraction over Hadoop's MapReduce framework, enabling users to interact with data using familiar SQL syntax. Users interact with Hive using Hive Query Language (HQL), a SQL-like language.
Getting acquainted with MongoDB will give you insights into how non-relationaldatabases can be used for advanced web applications, like the ones offered by traditional relationaldatabases. The underlying model is the crucial conceptual difference between MongoDB and other SQLdatabases.
ETL Data Engineers work with different data formats, such as structured, semi-structured, and unstructured data, and ensure that pipelines are efficient, scalable, and optimized for performance. Clean, reformat, and aggregate data to ensure consistency and readiness for analysis.
Top 15 Data Analysis Tools to Explore in 2025 | Trending Data Analytics Tools 1. Google Data Studio 10. Looker Data Analytics Tools Comparison Analyze Data Like a Pro with These Data Analysis Tools FAQs on Data Analysis Tools Data Analysis Tools- What are they? Power BI 4. Apache Spark 6.
In broader terms, two types of data -- structured and unstructured data -- flow through a data pipeline. The structureddata comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. Step 1- Automating the Lakehouse's data intake.
Data engineers leverage AWS Glue's capability to offer all features, from data extraction through transformation into a standard Schema. AWS Redshift Amazon Redshift offers petabytes of structured or semi-structureddata storage as an ideal data warehouse option.
Transform unstructured data into structureddata by fixing errors, redundancies, missing numbers, and other anomalies, eliminating unnecessary data, optimizing data systems, and finding relevant insights. to perform those tasks efficiently. that will play a significant role in your career.
create_engine (from sqlalchemy) used to create a connection to an SQLite database (or other databases) in a more flexible way than sqlite3, enabling easier integration with Pandas and SQL operations. def create_connection(dw_file): ''' create connection with data warehouse ''' try: conn = sqlite3.connect(dw_file)
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
Storage, Processing, & Analytics Following data collection, the stored data undergoes a series of transformative processes to prepare it for analysis. Based on scalability, performance, and datastructure, data is stored in suitable storage systems, such as relationaldatabases, NoSQL databases, or data lakes.
Let us compare traditional data warehousing and Hadoop-based BI solutions to better understand how using BI on Hadoop proves more effective than traditional data warehousing- Point Of Comparison Traditional Data Warehousing BI On Hadoop Solutions Data Storage Structureddata in relationaldatabases.
Moreover, anything you can do in SQL, you can do in Tableau. You can paste and refer your SQL queries to design anything in Tableau. Tableau's popularity stems from its ability to connect to various data sources. It can also extract information from unstructured data and convert it into structureddata.
This data can be analysed using big data analytics to maximise revenue and profits. Hive Project - Visualising Website Clickstream Data with Apache Hadoop 3. To this group, we add a storage account and move the raw data. Then we create and run an Azure data factory (ADF) pipelines.
7 Popular GCP ETL Tools You Must Explore in 2025 This section lists the topmost GCP ETL services/tools that will allow you to build effective data pipelines and workflows for your data engineering projects. Cloud SQL Cloud SQL is a completely managed relationaldatabase service for SQL Server, MySQL, and PostgreSQL.
Step 2: Database Management and Data Analysis Before you can build AI models, it's essential to know how to access, manage, and analyze data effectively. Start with SQL, the standard language for querying structureddata in relationaldatabases.
One of the main hindrances to getting value from our data is that we have to get data into a form that’s ready for analysis. Consider the hoops we have to jump through when working with semi-structureddata, like JSON, in relationaldatabases such as PostgreSQL and MySQL. It sounds simple, but it rarely is.
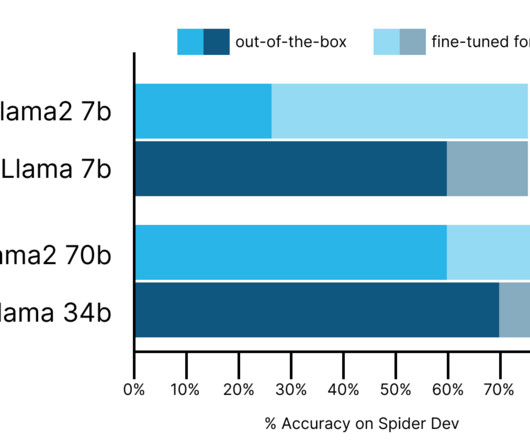
Code Llama models outperform Llama2 models by 11-30 percent-accuracy points on text-to-SQL tasks and come very close to GPT4 performance. SQL—the standard programming language of relationaldatabases—was not included in these benchmarks. We tested their skills at SQL generation by using a few-shot prompt specified here.
MapReduce performs batch processing only and doesn’t fit time-sensitive data or real-time analytics jobs. Data engineers who previously worked only with relationaldatabase management systems and SQL queries need training to take advantage of Hadoop. Cassandra excels at streaming data analysis.
As data processing requirements grow exponentially, NoSQL is a dynamic and cloud friendly approach to dynamically process unstructured data with ease.IT professionals often debate the merits of SQL vs. NoSQL but with increasing business data management needs, NoSQL is becoming the new darling of the big data movement.
Summary Data warehouses have gone through many transformations, from standard relationaldatabases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content