This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The default association with the term "database" is relational engines, but non-relational engines are also used quite widely. In this episode Oren Eini, CEO and creator of RavenDB, explores the nuances of relational vs. non-relational engines, and the strategies for designing a non-relationaldatabase.
Traditional relationaldatabasesystems are ubiquitous in software systems. They are surrounded by a strong ecosystem of tools, such as object-relational mappers and schema migration helpers. A tomicity in relationaldatabases ensures that a transaction either succeeds or fails as a whole.
What will the next important category of databases look like? For decades, relationaldatabases were the undisputed home of data. They powered everything: from websites to analytics, from customer data […].
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.
The simple idea was, hey how can we get more value from the transactional data in our operational systems spanning finance, sales, customer relationship management, and other siloed functions. There was no easy way to consolidate and analyze this data to more effectively manage our business. But simply moving the data wasnt enough.
Anyone who’s been roaming around the forest of Data Engineering has probably run into many of the newish tools that have been growing rapidly around the concepts of Data Warehouses, Data Lakes, and Lake Houses … the merging of the old relationaldatabase functionality with TB and PB level cloud-based file storage systems.
Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew. The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems.
One of the most common relationaldatabasesystems that connects to Apache Kafka® is Oracle, which often holds highly critical enterprise transaction workloads. While Oracle Database (DB) excels at many […].
A popular open-source relationaldatabase used by several organizations across the world is PostgreSQL. It is a perfect database management system that also assists developers to build applications, and administrators to protect data integrity and develop fault-tolerant environments. […]
Data engineering function involve the fundamental understanding of data utilization skills such as coding, python, SQL database, relationaldatabase, AWS in the field of big data. It would even be an additional benefit for them to have expertise in computer networking as well.
Business transactions captured in relationaldatabases are critical to understanding the state of business operations. To avoid disruptions to operational databases, companies typically replicate data to data warehouses for analysis.
PostgreSQL is one of the most popular open-source choices for relationaldatabases. It is loved by engineers for its powerful features, flexibility, efficient data retrieval mechanism, and on top of all its overall performance. However, performance issues can be encountered with the growth in the size of data and complexity of queries.
SnowConvert is an easy-to-use code conversion tool that accelerates legacy relationaldatabase management system (RDBMS) migrations to Snowflake. In addition to free assessments and free table conversions, SnowConvert now supports accurate conversion of database views from Teradata, Oracle or SQL Server for free.
We take advantage of this feature in our ad bidding systems, maintaining consistent data views from our Account Specialists’ spreadsheets, to our Data Scientists’ notebooks, to our bidding system’s in-memory data. A Unified View for Operational Data We kept most of our operational data in relationaldatabases, like MySQL.
Meanwhile, customers are responsible for protecting resources within the cloud, including operating systems, applications, data, and the configuration of security controls such as Identity and Access Management (IAM) and security groups. Shared Controls Responsibilities are split between AWS and the customer.
For more than 40 years, relationaldatabases have been managed and modified using the programming language SQL (Structured Query Language). A versatile tool for companies that need to handle data across several systems, SQL is also a language that can be utilized on a variety of platforms and operating systems.
Snowflake’s relationaldatabase, especially when paired with Snowpark , enables much quicker use of data for ML model training and testing. While some of the data we collect comes from existing systems such as a CRM or an EMS, first-party data that’s being collected from websites only lives in Hum.
These experts are well-versed in programming languages, have access to databases, and have a broad understanding of topics like operating systems, debugging, and algorithms. Computer programs and related materials like specifications, design models, and user guides. " The software consists of several connected programs.
A solid understanding of relationaldatabases and SQL language is a must-have skill, as an ability to manipulate large amounts of data effectively. A Data Engineer also designs, builds, integrates, and manages large-scale data processing systems. What is the difference between a relational and a non-relationaldatabase?
In this episode the head of product at Tamr, Mark Marinelli, discusses the challenges of building a master data set, why you should have one, and some of the techniques that modern platforms and systems provide for maintaining it. How does the master data set get used within the overall analytical and processing systems of an organization?
The system automatically replicates information to prevent data loss in the case of a node failure. Each Hadoop cluster has three functional layers: storage layer created by Hadoop’s native file system — HDFS, resource management layer represented by YARN, and. A file stored in the system ?an’t cost-effectiveness. fail-safety.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription TimescaleDB, from your friends at Timescale, is the leading open-source relationaldatabase with support for time-series data. Time-series data is time stamped so you can measure how a system is changing.
Lior then neatly tied the bow with feature highlights showing just how Monte Carlo provides visibility into the data, systems, and code in quick succession. As an industry we think a lot about the six dimensions of data quality , but at Monte Carlo we spend just as much time thinking about the three root causes of data downtime,” he said.
Contact Info Peter LinkedIn petermattis on GitHub @petermattis on Twitter Cockroach Labs @CockroackDB on Twitter Website cockroachdb on GitHub Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
Ingest and transform easily in a single system without having to stitch solutions together or build additional data pipelines to move data around. The new database connectors are built on top of Snowpipe Streaming, which means they also provide more cost-effective and lower latency pipelines for customers.
What has changed in recent years to allow for the current proliferation of graph oriented storage systems? What are some of the common uses of graph storage systems? What are your opinions on the graph query languages that have been adopted by other storages systems, such as Gremlin, Cypher, and GSQL?
Summary At the foundational layer many databases and data processing engines rely on key/value storage for managing the layout of information on the disk. RocksDB is one of the most popular choices for this component and has been incorporated into popular systems such as ksqlDB. What is the integration process for adopting SpeeDB?
Databases are utilized in back-end engineering to store and process information. Databases can be used to input information into systems, fetch it whenever required, change already existing data, or remove useful data that is no longer useful.
Links Alooma Convert Media Data Integration ESB (Enterprise Service Bus) Tibco Mulesoft ETL (Extract, Transform, Load) Informatica Microsoft SSIS OLAP Cube S3 Azure Cloud Storage Snowflake DB Redshift BigQuery Salesforce Hubspot Zendesk Spark The Log: What every software engineer should know about real-time data’s unifying abstraction by Jay (..)
What’s forgotten is that the rise of this paradigm was driven by a particular type of human-facing application in which a user looks at a UI and initiates actions that are translated into database queries. Because databases don’t model the flow of data, the interconnection between systems in a company is a giant mess.
TimescaleDB, from your friends at Timescale, is the leading open-source relationaldatabase with support for time-series data. Time-series data is time stamped so you can measure how a system is changing. Time-series data is relentless and requires a database like TimescaleDB with speed and petabyte-scale.
This is the fifth post in a series by Rockset's CTO and Co-founder Dhruba Borthakur on Designing the Next Generation of Data Systems for Real-Time Analytics. Typically stored in SQL statements, the schema also defines all the tables in the database and their relationship to each other.
It was the "Cambrian explosion" of the usage of relationaldatabases, spreadsheets, and slide decks. It did that by implementing a recommender system based on machine learning. This phase also mediated the development of business intelligence and the implementation of descriptive analytics [ , 8 ] to monitor business metrics.
Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machine learning—your relationaldatabase might not be enough. relationaldatabases) and storing them in an intermediate broker.
FaunaDB is a cloud native database built by the engineers behind Twitter’s infrastructure and designed to serve the needs of modern systems. FaunaDB is a cloud native database built by the engineers behind Twitter’s infrastructure and designed to serve the needs of modern systems.
HDP customers only: Which relationaldatabase and version is used? How many database objects do you have? This utility raises awareness of clusters that may present risks during an upgrade to CDP due to, for example, an unsupported of the operating system currently in use. On an HDP Cluster, use SmartSense.
Data integrity is based on four main pillars: Data integration : Regardless of its original source, on legacy systems, relationaldatabases, or cloud data warehouses, data must be seamlessly integrated in order to gain visibility into all your data in a timely fashion.
Classic relationaldatabase management systems (RDBMS) distribute and organize data in a relatively static storage layer. When queries are requested, they compute on the stored data and then return results […].
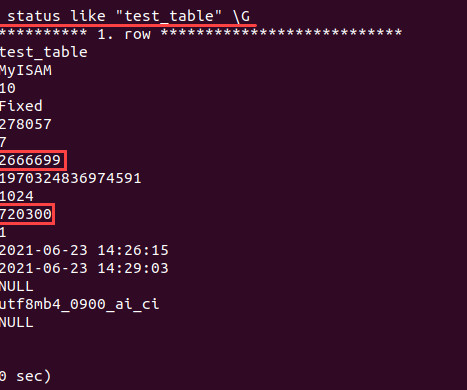
MySQL is a relationaldatabase management system based on the Structured Query Language (SQL), the most widely used language for accessing and managing database records. Under the GNU license, MySQL is open-source and free software. Oracle Corporation backs it up.
PostgreSQL is an open-source RelationalDatabase taking the world by storm, both on the ground and up there in the Cloud. It is one of the most advanced RelationalDatabases out there offering standard SQL features along with some modern ones like triggers, transaction integrity, etc.
PostgreSQL is an open-source RelationalDatabase taking the world by storm, both on the ground and up there in the Cloud. It is one of the most advanced RelationalDatabases offering standard SQL features along with some modern ones like triggers, transaction integrity, etc.
This programming language is used for general purposes and is a robust system. Here are some things that you should learn: Recursion Bubble sort Selection sort Binary Search Insertion Sort Databases and Cache To build a high-performance system, programmers need to rely on the cache. Put the system logic in order.
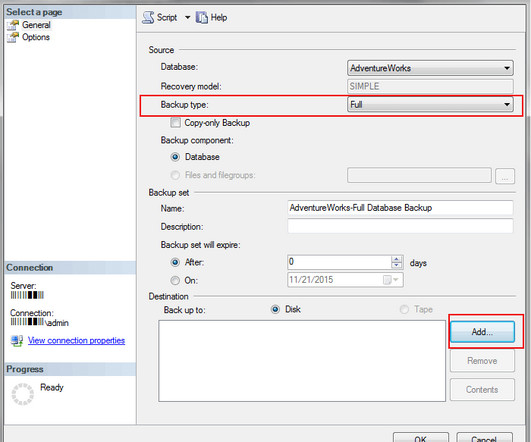
Microsoft SQL Server (MSSQL) is a popular relationaldatabase management application that facilitates data storage and access in your organization. Backing up and restoring your MSSQL database is crucial for maintaining data integrity and availability. In the event of system failure or […]
MySQL is a RelationalDatabase Management System. At the core of the MySQL Database lies […] This Open-source tool is one of the best RDBMS available in the market that is being used to develop web-based software applications among others. It houses a Client-Server architecture.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content