This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Considering how most industries have rapidly evolved thanks to technology, upgrading grids has been of utmost importance for utility companies out there. The application of Artificial Intelligence (AI) technology into grid structures is now a game changer for utility managers.
The energy and utility industry is being transformed by AI technology, and it is powered by the digital revolution. One of its newest forms, Generative AI, is bolstering utility operations reliability, efficiency, and resilience. Its place in modern utilities is most evident in real-time fault detection.
Modern IT environments require comprehensive data for successful AIOps, that includes incorporating data from legacy systems like IBM i and IBM Z into ITOps platforms. AIOps presents enormous promise, but many organizations face hurdles in its implementation: Complex ecosystems made of multiple, fragmented systems that lack interoperability.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. It enhances the traceability of data flows within systems, ultimately empowering developers to swiftly implement privacy controls and create innovative products. Hack, C++, Python, etc.)
This will help you decide whether to build an in-house entity resolution system or utilize an existing solution like the Senzing® API for entity resolution. By the end, you'll understand what to look for, the most common mistakes and pitfalls to avoid, and your options.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.
Tail utilization is a significant system issue and a major factor in overload-related failures and low compute utilization. The tail utilization optimizations at Meta have had a profound impact on model serving capacity footprint and reliability. Why is tail utilization a problem?
The name comes from the concept of “spare cores:” machines currently unused, which can be reclaimed at any time, that cloud providers tend to offer at a steep discount to keep server utilization high. Spare Cores attempts to make it easier to compare prices across cloud providers. Source: Spare Cores. Tech stack.
An operating system that allows multiple programmes to run simultaneously on a single processor machine is known as a multiprogramming operating system. This keeps the system from idly waiting for the I/O work to finish, wasting CPU time. We'll explain the multiprogramming operating system in this article.
Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. We believe that privacy drives product innovation.
Responsible for building and maintaining developer tools so the programmer and copilot can do their jobs better; such as improving editors, building better debugging functionality, creating utility tools and macros, etc. Brooks discusses software in the context of producing operating systems, pre-internet. The tester.
Strobelight combines several technologies, many open source, into a single service that helps engineers at Meta improve efficiency and utilization across our fleet. Engineers and developers can use this information to identify performance and resource bottlenecks, optimize their code, and improve utilization. Python, Java, and Erlang).
We’re introducing Arcadia, Meta’s unified system that simulates the compute, memory, and network performance of AI training clusters. We need a systemized source of truth that can simulate various performance factors across compute, storage, and network collectively. For instance, the AI Research SuperCluster for AI research.
Not only could this recommendation system save time browsing through lists of movies, it can also give more personalized results so users don’t feel overwhelmed by too many options. What are Movie Recommendation Systems? Recommender systems have two main categories: content-based & collaborative filtering.
From Sella’s status page : “Following the installation of an update to the operating system and related firmware which led to an unstable situation. Still, I’m puzzled by how long the system has been down. If it was an update to Oracle, or to the operating system, then why not roll back the update?
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
Failures in a distributed system are a given, and having the ability to safely retry requests enhances the reliability of the service. Implementing idempotency would likely require using an external system for such keys, which can further degrade performance or cause race conditions.
Managing and utilizing data effectively is crucial for organizational success in today's fast-paced technological landscape. Agentic AI refers to AI systems that act autonomously on behalf of their users. These systems make decisions, learn from interactions and continuously improve without constant human intervention.
I have comprehensively analyzed the area of physical security, particularly the ongoing discussion surrounding fail safe vs fail-safe secure electric strike locking systems. On the other hand, fail-secure systems focus on maintaining continuous security, keeping doors locked even in difficult conditions to protect assets.
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. We dabbled in network engineering, database management, and system administration. and hand-rolled C -code.
In particular, our machine learning powered ads ranking systems are trying to understand users’ engagement and conversion intent and promote the right ads to the right user at the right time. Specifically, such discrepancies unfold into the following scenarios: Bug-free scenario : Our ads ranking system is working bug-free.
KAWA Analytics Digital transformation is an admirable goal, but legacy systems and inefficient processes hold back many companies efforts. PTA Robotics PTA Robotics AI-powered vineyard disease prediction system leverages drone imagery, Internet of Things data and weather insights to detect vineyard disease risks before symptoms appear.
Juraj included system monitoring parts which monitor the server’s capacity he runs the app on: The monitoring page on the Rides app And it doesn’t end here. Juraj created a systems design explainer on how he built this project, and the technologies used: The systems design diagram for the Rides application The app uses: Node.js
This is particularly true in the data center space, where new protocols like Precision Time Protocol (PTP) are allowing systems to be synchronized down to nanosecond precision. The service continues to utilize TAI timestamps but can return UTC timestamps to clients via the API. microseconds.
The MIT report identifies three common challenges: Data silos and fragmentation: Disconnected systems prevent organizations from accessing the full value of their data. Underdeveloped AI governance: Without strong governance frameworks, businesses struggle with trust, security and compliance in their AI systems.
The company utilizes Google Cloud to some extent, and my understanding from talking with Twitter engineers is that this was for machine learning (ML) use cases. Bots and bad actors are present on all social media platforms, and detecting, limiting or banning these accounts is typically done by ML systems which detect suspicious patterns.
But there’s no “one size fits all” strategy when it comes to deciding the right balance between utilizing the cloud and operating your infrastructure on-premises. What are the use cases where the company already utilizes public cloud? Agoda utilizes Akamai as its CDN vendor. Agoda in numbers Agoda lists 3.6M
I have confirmed this through talking with software engineers there, who told me there’s a top-down mandate to utilize AI wherever possible in an effort to drive more efficiency, and product improvements. With clever-enough probing, this system prompt can be revealed. ” What is the system prompt for Klarna’s bot?
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This blog series will examine the tools, techniques, and strategies we have utilized to achieve this goal.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
I find it harder to work with a system that will happily undertake any task, whether it is simple, yet ambiguous, or complex and far beyond its own capabilities. Hallucinations are of course an issue too, but they seem quite minor in comparison. I can live with occasional factual errors, and the need to review the output.
Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems.
[link] Whatnot: Evolving Feed Ranking at Whatnot Whatnot describes their transition from a batch prediction system to an online inference framework for ranking, which is shown in their "For You Feed." link] Henry Zhu: An Intro to DeepSeek's Distributed File System The author gives an overview of DeepSeek’s file system.
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Support Data Engineering Podcast Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems.
Kafka is designed to be a black box to collect all kinds of data, so Kafka doesn't have built-in schema and schema enforcement; this is the biggest problem when integrating with schematized systems like Lakehouse. If you want to build OLAP systems for low-latency complex queries, use Pinot. When to use Fluss vs Apache Pinot?
This is crucial for applications that require up-to-date information, such as fraud detection systems or recommendation engines. Data Integration : By capturing changes, CDC facilitates seamless data integration between different systems. Finally, the control plane emits enriched metrics to enable effective monitoring of the system.
ThoughtSpot prioritizes the high availability and minimal downtime of our systems to ensure a seamless user experience. In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. What is metadata?
This elasticity allows data pipelines to scale up or down as needed, optimizing resource utilization and cost efficiency. Utilize Cloud-Native Tools: Leverage cloud-native data pipeline tools like Ascend to build and orchestrate scalable workflows. Regularly review usage patterns and adjust cloud resource allocation as needed.
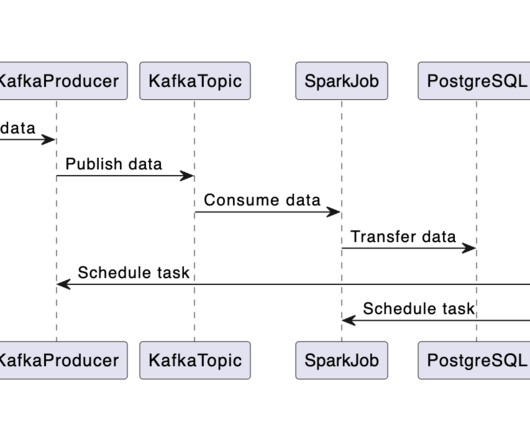
Ideal for those new to data systems or language model applications, this project is structured into two segments: This initial article guides you through constructing a data pipeline utilizing Kafka for streaming, Airflow for orchestration, Spark for data transformation, and PostgreSQL for storage. You can also leave the port at 5432.
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines. I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling.
DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL). Many articles explain how DeepSeek works, and I found the illustrated example much simpler to understand.
We focused on building end-to-end AI systems with a major emphasis on researcher and developer experience and productivity. Grand Teton builds on the many generations of AI systems that integrate power, control, compute, and fabric interfaces into a single chassis for better overall performance, signal integrity, and thermal performance.
Summary Data systems are inherently complex and often require integration of multiple technologies. Orchestrators are centralized utilities that control the execution and sequencing of interdependent operations. Can you start by defining what data orchestration is and how it differs from other types of orchestration systems?
Before we start: plenty of people who subscribe to the newsletter utilize a learning and development budget their company provides. However, it can compete by offering tools for companies to utilize their own internal knowledge bases, and by ensuring that internal company data doesn’t leave the premises.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content