This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hi, this is Gergely with a bonus issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. This article is one out of five sections from The Pulse #119. Full subscribers received this issue a week and a half ago. To get articles like this in your inbox, subscribe here.
Since I started working in tech, one goal that kept coming up was workflow automation. Whether automating a report or setting up retraining pipelines for machine learning models, the idea was always the same: do less manual work and get more consistent results. But automation isnt just for analytics. RevOps teams want to streamline processes… Read more The post Best Automation Tools In 2025 for Data Pipelines, Integrations, and More appeared first on Seattle Data Guy.
HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. There are multiple ways to start a new year, either with new projects, new ideas, new resolutions or by just keeping doing the same music. I hope you will enjoy 2025. The Data News are here to stay, the format might vary during the year, but here we are for another year. Thank you so much for your support through the years.
Artificial Intelligence (AI) is all the rage, and rightly so. By now most of us have experienced how Gen AI and the LLMs (large language models) that fuel it are primed to transform the way we create, research, collaborate, engage, and much more. Yet along with the AI hype and excitement comes very appropriate sanity-checks asking whether AI is ready for prime-time.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
If AI agents are going to deliver ROI, they need to move beyond chat and actually do things. But, turning a model into a reliable, secure workflow agent isn’t as simple as plugging in an API. In this new webinar, Alex Salazar and Nate Barbettini will break down the emerging AI architecture that makes action possible, and how it differs from traditional integration approaches.
Apache Iceberg is a modern table format designed to overcome the limitations of traditional Hive tables, offering improved performance, consistency, and scalability. In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern data lakes. Well also dive into […] The post How to Use Apache Iceberg Tables?
1. Introduction 2. Centralize Metric Definitions in Code Option A: Semantic Layer for On-the-Fly Queries Option B: Pre-Aggregated Tables for Consumers 3. Conclusion & Recap 4. Required Reading 1. Introduction If youve worked on a data team, youve likely encountered situations where multiple teams define metrics in slightly different ways, leaving you to untangle why discrepancies exist.
Rethinking Object Storage: A First Look at CloudflareR2 and Its BuiltIn ApacheIceberg Catalog Sometimes, we follow tradition because, well, it worksuntil something new comes along and makes us question the status quo. For many of us, AmazonS3 is that welltrodden path: the backbone of our data platforms and pipelines, used countless times each day. If […] The post Cloudflare R2 Storage with Apache Iceberg appeared first on Confessions of a Data Guy.
Rethinking Object Storage: A First Look at CloudflareR2 and Its BuiltIn ApacheIceberg Catalog Sometimes, we follow tradition because, well, it worksuntil something new comes along and makes us question the status quo. For many of us, AmazonS3 is that welltrodden path: the backbone of our data platforms and pipelines, used countless times each day. If […] The post Cloudflare R2 Storage with Apache Iceberg appeared first on Confessions of a Data Guy.
In this episode of Unapologetically Technical, I interview Adrian Woodhead, a distinguished software engineer at Human and a true trailblazer in the European Hadoop ecosystem. Adrian, who even authored a chapter in the seminal work “Hadoop: The Definitive Guide,” shares his remarkable journey through the tech world, from his roots in South Africa to his current role pushing the boundaries of data engineering.
Data lineage is an instrumental part of Metas Privacy Aware Infrastructure (PAI) initiative, a suite of technologies that efficiently protect user privacy. It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. This allows us to verify that our users everyday interactions are protected across our family of apps, such as their religious views in the Facebook Dating app, the example well walk through in this
Using cloud managed services is often a love and hate story. On one hand, they abstract a lot of tedious administrative work to let you focus on the essentials. From another, they often have quotas and limits that you, as a data engineer, have to take into account in your daily work. These limits become even more serious when they operate in a latency-sensitive context, as the one of stream processing.
Many data engineers and analysts start their journey with Postgres. Postgres is powerful, reliable, and flexible enough to handle both transactional and basic analytical workloads. It’s the Swiss Army knife of databases, and for many applications, it’s more than sufficient. But data volumes grow, analytical demands become more complex, and Postgres stops being enough.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
We want to capture an accurate snapshot of software engineering, today – and need your help! Tell us about your tech stack and get early access to the final report, plus extra analysis We’d like to know what tools, languages, frameworks and platforms you are using today. Which tools/frameworks/languages are popular and why?
Planning out your data infrastructure in 2025 can feel wildly different than it did even five years ago. The ecosystem is louder, flashier, and more fragmented. Everyone is talking about AI, chatbots, LLMs, vector databases, and whether your data stack is “AI-ready.” Vendors promise magic, just plug in their tool and watch your insights appear.… Read more The post How To Set Up Your Data Infrastructure In 2025 Part 1 appeared first on Seattle Data Guy.
Though AI is (still) the hottest technology topic, its not the overriding issue for enterprise security in 2025. Advanced AI will open up new attack vectors and also deliver new tools for protecting an organizations data. But the underlying challenge is the sheer quantity of data that overworked cybersecurity teams face as they try to answer basic questions such as, Are we under attack?
LLMs are not just limited by hallucinationsthey fundamentally lack awareness of their own capabilities, making them overconfident in executing tasks they dont fully understand. While vibe coding embraces AIs ability to generate quick solutions, true progress lies in models that can acknowledge ambiguity, seek clarification, and recognise when they are out of their depth.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
If you’re working with AI/ML workloads(like me) and trying to figure out which data format to choose, this post is for you. Whether you’re a student, analyst, or engineer, knowing the differences between Apache Iceberg, Delta Lake, and Apache Hudi can save you a ton of headaches when it comes to performance, scalability, and real-time […] The post Apache Iceberg vs Delta Lake vs Hudi: Best Open Table Format for AI/ML Workloads appeared first on Analytics Vidhya.
dbt is the standard for creating governed, trustworthy datasets on top of your structured data. MCP is showing increasing promise as the standard for providing context to LLMs to allow them to function at a high level in real world, operational scenarios. Today, we are open sourcing an experimental version of the dbt MCP server. We expect that over the coming years, structured data is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provision
Every once in a great while, the question comes up: “How do I test my Databricks codebase?” It’s a fair question, and if you’re new to testing your code, it can seem a little overwhelming on the surface. However, I assure you the opposite is the case. Testing your Databricks codebase is no different than […] The post Testing and Development for Databricks Environment and Code. appeared first on Confessions of a Data Guy.
In this episode of Unapologetically Technical, I interview Semih Salihoglu, Associate Professor at the University of Waterloo and co-founder and CEO of Kuzu. Semih is a researcher and entrepreneur with a background in distributed systems and databases. He shares his journey from a small city in Turkey to the hallowed halls of Yale University, where he studied computer science and economics.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Were sharing details about Strobelight, Metas profiling orchestrator. Strobelight combines several technologies, many open source, into a single service that helps engineers at Meta improve efficiency and utilization across our fleet. Using Strobelight, weve seen significant efficiency wins, including one that has resulted in an estimated 15,000 servers worth of annual capacity savings.
A few months ago I wrote a blog post about event skew and how dangerous it is for a stateful streaming job. Since it was a high-level explanation, I didn't cover Apache Spark Structured Streaming deeply at that moment. Now the watermark topic is back to my learning backlog and it's a good opportunity to return to the event skew topic and see the dangers it brings for Structured Streaming stateful jobs.
The database landscape has reached 394 ranked systems across multiple categoriesrelational, document, key-value, graph, search engine, time series, and the rapidly emerging vector databases. As AI applications multiply quickly, vector technologies have become a frontier that data engineers must explore. The essential questions to be answered are: When should you choose specialized vector solutions like Pinecone, Weaviate, or Qdrant over adding vector extensions to established databases like Post
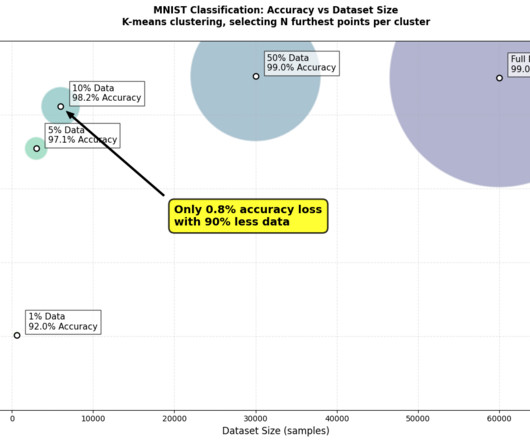
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. I experimented with data pruning on MNIST to classify handwritten digits. Best runs for furthest-from-centroid selection compared to full dataset. Image byauthor. What if I told you that using just 50% of your training data could achieve better results than using the fulldataset?
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
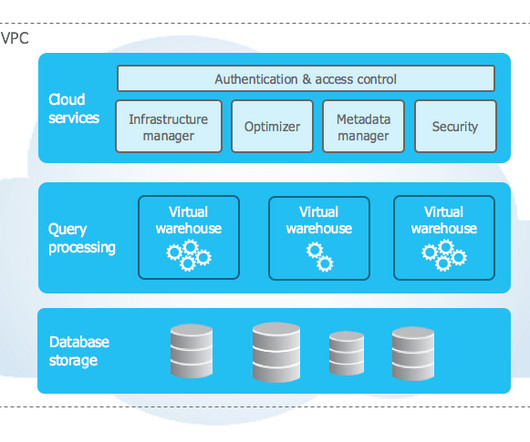
Over the past three years our teams have noticed a pattern. Many companies looking to migrate to the cloud go from SQL Server to Snowflake. There are many reasons this makes sense. One of the reasons and common benefits was that teams found it far easier to manage that SQL Server and in almost every… Read more The post How To Migrate From SQL Server To Snowflake appeared first on Seattle Data Guy.
Despite the best efforts of many ML teams, most models still never make it to production due to disparate tooling, which often leads to fragmented data and ML pipelines and complex infrastructure management. Snowflake has continuously focused on making it easier and faster for customers to bring advanced models into production. In 2024, we launched over 200 AI features, including a full suite of end-to-end ML features in Snowflake ML , our integrated set of capabilities for machine learning mode
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. (Refer to our recent overview for more details). However, as we expanded our set of personalization algorithms to meet increasing business needs, maintenance of the recommender system became quite costly.
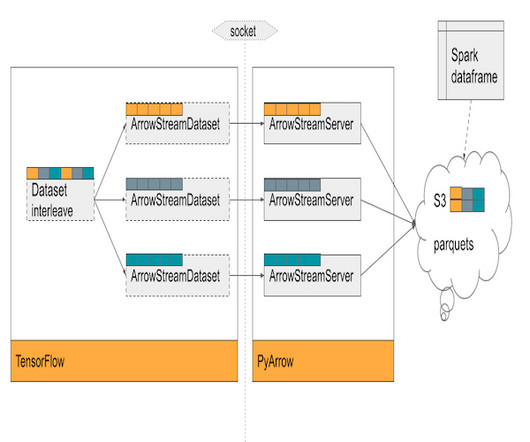
At Yelp, we encountered challenges that prompted us to enhance the training time of our ad-revenue generating models, which use a Wide and Deep Neural Network architecture for predicting ad click-through rates (pCTR). These models handle large tabular datasets with small parameter spaces, requiring innovative data solutions. This blog post delves into our journey of optimizing training time using TensorFlow and Horovod, along with the development of ArrowStreamServer, our in-house library for lo
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Key Takeaways: Prioritize metadata maturity as the foundation for scalable, impactful data governance. Recognize that artificial intelligence is a data governance accelerator and a process that must be governed to monitor ethical considerations and risk. Integrate data governance and data quality practices to create a seamless user experience and build trust in your data.
Building fun things is a real part of Data Engineering. Using your creative side when building a Lake House is possible, and using tools that are outside the normal box can sometimes be preferable. Checkout this video where I dive into how I build just such a Lake House using Modern Data Stack tools like […] The post Building a Fast, Light, and CHEAP Lake House with DuckDB, Delta Lake, and AWS Lambda appeared first on Confessions of a Data Guy.
Data is at the core of everything, from business decisions to machine learning. But processing large-scale data across different systems is often slow. Constant format conversions add processing time and memory overhead. Traditional row-based storage formats struggle to keep up with modern analytics. This leads to slower computations, higher memory usage, and performance bottlenecks.
In 2024, our bug bounty program awarded more than $2.3 million in bounties, bringing our total bounties since the creation of our program in 2011 to over $20 million. As part of our defense-in-depth strategy , we continued to collaborate with the security research community in the areas of GenAI, AR/VR, ads tools, and more. We also celebrated the security research done by our bug bounty community as part of our annual bug bounty summit and many other industry events.
Speaker: Jay Allardyce, Deepak Vittal, Terrence Sheflin, and Mahyar Ghasemali
As we look ahead to 2025, business intelligence and data analytics are set to play pivotal roles in shaping success. Organizations are already starting to face a host of transformative trends as the year comes to a close, including the integration of AI in data analytics, an increased emphasis on real-time data insights, and the growing importance of user experience in BI solutions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content